スマートグリッド時代に生まれる新しい「情報」
〔1〕新しい「情報」の流通
従来、電力消費量のデータは、アナログの電力メーターによって各家庭が契約している電力会社のみが把握していた。しかし、各家庭にスマートメーターが設置されると、そのときそのときの電力使用状況が詳細に記録され、情報が取得できるようになる。現状では、まだスマートメーターなどが各家庭に設置されておらず、法律の整備など議論すべき課題もあるため、この情報がすぐに使用されるということはない。しかし、近い将来にはこれらの課題が解決され、各家庭の電力使用量がスマートメーターを通して電力会社やアグリゲータ注1に送信されるようになれば、各家庭の電力消費データを活用した新しいサービスやビジネスも可能となる。
例えば、需要家(消費者)からすると、電力会社や新電力から日々の使用量に合わせた効率的な電力の購入が実現でき、経済的になる。また、供給側からすると、デマンドレスポンス(電力の需要と供給の制御)が行えるなど、さまざまなメリットがある。
2016年の電力自由化はさまざまな形の電力契約を可能とするため、そのもととなる電力消費データの重要性はさらに増すといえる。しかし一方で、アグリゲータが情報を入手したり、電力会社とアグリゲータ間で情報のやりとりが行われたりといったように、各家庭から取得された情報が、ネットワーク上で頻繁に流通することになり、情報漏えいの危険度が増してくる。
〔2〕スマートメーターに記録される情報
それでは、実際にスマートメーターに記録される情報とはどういったものなのか。それを図1に示す。
図1 スマートメーターに記録される電力消費量データの例
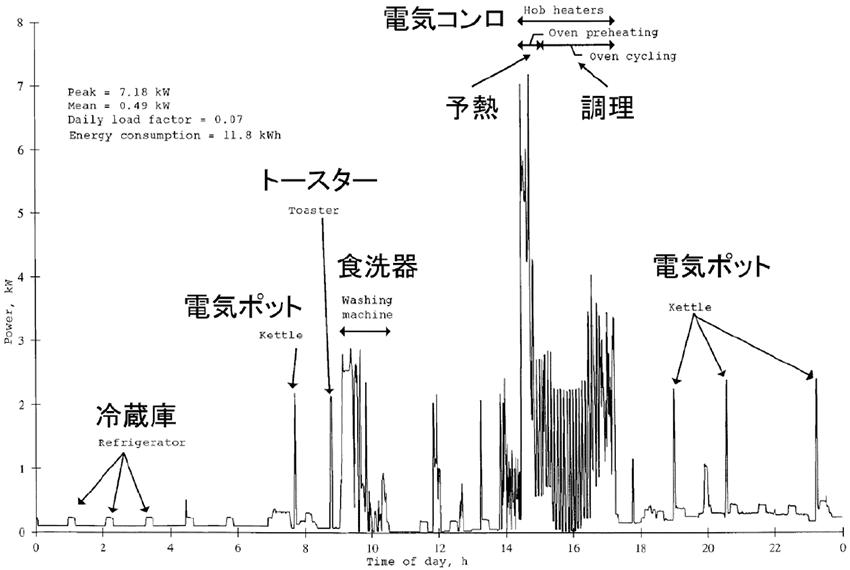
〔G. Wood & M. Newborough, Dynamic Energy-consumption Indicators for Domestic Appliances: ,IEE Proceedings of Generation Transmission and Distribution 146 (3) (1999) 283-293).より、注釈追加〕
図1に示す電力消費量の折れ線グラフの波形には、大きな特徴があることが見て取れる。この特徴を分析することで、その家庭の情報をある程度推定することが可能となる。
例えば、電力消費量によっては、所得の大小が想定できるであろうし、電力消費の時間帯を見ることによって、その家庭の生活スタイルや家族構成なども見えてくる。さらに、各メーカーの家電製品は、使用時に固有の電力波形が発生するため、そのデータベースと照合すれば、その家庭が、どのメーカーのどの種類の家電製品を使っているかも推定できる可能性がある。このように、電力消費量の情報は、多分に個人情報を含んでいると言える。
しかし、前述したデマンドレスポンスをはじめとするスマートメーターの情報の有効活用は、各家庭からの電力使用情報なしでは実現することができない。
この問題を解決するため、慶應義塾大学理工学部 システムデザイン工学科の西宏章教授は、各家庭の電力使用量を匿名化注2して使用する技術を考案した。次に、この内容について詳しく見ていく。
個人情報と匿名化
個人情報とは、その情報自体によって、特定の個人を識別できる情報を指す。利用される目的によっては、個人の権利や利益、プライバシーを損なう可能性があるため、法律で保護されているが、同時に、さまざまな業界において、非常に有用性の高い情報でもある。
例えば、医療業界では、どの年齢のどういった生活サイクルの人がどのような病気にかかりやすいかといったような傾向を導き出すことで、治療に役立てることができ、その結果、個人情報の提供者も利益を享受できる。
しかし、個人情報の過多な利用は、情報漏えいの危険性も増す。そのため、情報の有用性は損なわずに、一方で情報からは特定の個人を識別できないようにする「匿名化」が重要になる。
〔1〕k-member clustering手法
匿名化に関しては、さまざまな手法があるが、オーソドックスな方法としては、k- mem-ber clustering(ケー・メンバー・クラスタリング)がある。この方法は、あるデータの集合があった場合、データをk個ずつのクラスタ(まとまり)に分けることで、k個までは特定できるが、それ以上は特定することができない状態に匿名化する方法である。
具体的に図2で解説すると、この図では、横軸が電力使用量、各点は各家庭の電力使用量を表している。そして、kの値を3(k=3)として、データを3つごとのまとまりに分けて扱っている。このようにクラスタリングした情報を匿名化するには、それぞれのクラスタのデータの上限と下限のみを提示するという方法がある。しかし、これでは、各クラスタの上限と下限の値をもつデータの存在が明らかになってしまい、電力消費量のデータに対してこの匿名化を行った場合、1つのクラスタのうち2つの家庭の電力消費量データが意図に反して漏えいする。そこで、ノイズを加えて境界を曖昧にする方法も提案されている。
図2 k-member clusteringの例(k=3)
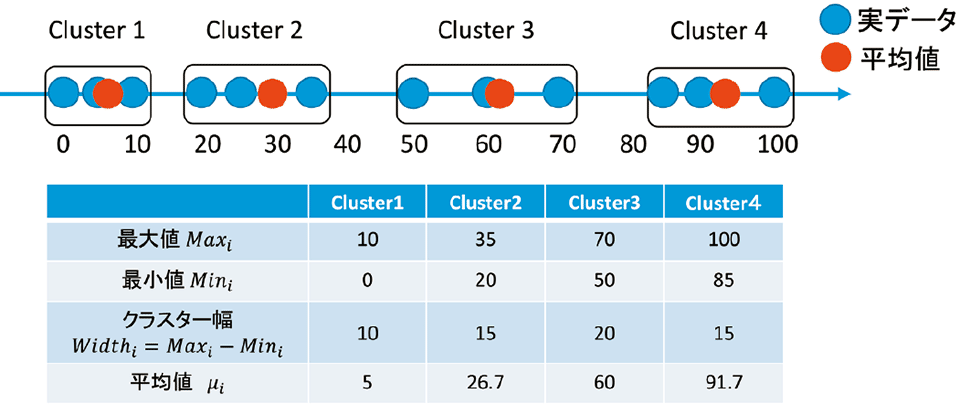
〔出所 西宏章氏資料より〕
また、各クラスタの平均値のみを提示するという方法もある。ところが、この方法では、各クラスタの幅がわからないことに加えて、分布の密度の情報が失われている。電力利用分布など、おおよその分布を知りたい場合、その分布がグラフで表現できる方法が扱いやすいといえる。
〔2〕適正なデマンドレスポンス
次に、改めて適正なデマンドレスポンスとはどういったものかを考えてみたい。
デマンドレスポンスとは、電力の市場価格が高騰しそうな場合や、需要量が供給量を逼迫しそうな場合に、各家庭や各マンション、各拠点などに向けて、一定の電力を節約するよう促し、電力使用の制御を行うシステムである。つまり、デマンドレスポンスを実現するためには、全体の電力使用量の予測のために、各家庭の電力使用量データが必要になる。
しかし、もし個人情報取り扱いのリスクの観点から、各家庭の詳細な電力使用量データを使用せず、データの合計値のみを使用すると、通常時に電力使用が多い家庭に対しても、少ない家庭に対しても、一律の割合で電力の制御を促すことになる。
これでは、普段、電力の節約を意識しないで電力を消費している家庭のほうが、電力制御時には電力を自由に使えるという不公平を生んでしまいかねず、適正なデマンドレスポンスの実施とはいえない。
このことからも、適正なデマンドレスポンスを実現するためには、各家庭の電力使用量データの分布密度などの情報を失わず、個人情報を保護して利用することが望ましい。
▼ 注1
アグリゲータ:デマンドレスポンス・アグリゲータのこと。電力会社などからのデマンドレスポンスの要請に対して、複数の需要家に対して電力使用の制御を行い、電力会社と節電気(ネガワット)の取引を行う。
▼ 注2
匿名化:あるデータを、そのデータの傾向などの情報は損なわずに、特定の個別データは判別できない状態に加工すること。