





このコーナーでは、最新のICT(情報通信技術)のキーワードをQ&A形式でわかりやすく解説していきます。
ブロードバンド時代の急速な進展を背景に、通信と放送の融合が注目され、本格的な画像コミュニケーション時代が到来しています。このような時代の要請に対応して、新しい「H.264/AVC」という画像圧縮技術が標準化され、国際的な注目を集めています。今回は、圧縮された情報の復号化について解説します。

Q7:圧縮情報をどう復号するか?
アナログの入力画像はどのように圧縮され、相手に伝えられて復元(復号)されるのでしょうか。その仕組みをわかりやすく説明してください。
≪1≫デジタル化した画像を圧縮する
図1-8は、実際に富士山の麓(ふもと)を走る新幹線の風景を、標準テレビ用のビデオ・カメラで撮影し、撮影したアナログ画像を124Mbpsの非圧縮PCM(先のQ.4のA.4で解説している)に変換し、MPEG-2の符号器(エンコーダ)に入力しています。次に、MPEG-2の符号器によって124Mbps(入力テレビ画像)は30分の1の4Mbpsに圧縮され、ブロードバンド回線で送信し、受信側でMPEG-2の復号器で元の画像に復号し、標準テレビで楽しむプロセスを概略的に説明しています。

図1-8 標準テレビ画像をMPEG-2で圧縮し送信する仕組み(クリックで拡大)
このプロセスを図1-9で、もう少し詳しくみて見ましょう。図1-9に示すように、被写体が発する光を捉えたテレビ・カメラからのアナログ情報は、A/D変換器(Analog to Digital Converter、アナログ/デジタル変換器)でデジタル化されます(非圧縮のPCM方式でデジタル化)。このA/D変換器は、以前は独立した装置だったこともありますが、現在ではLSI化され、多くは符号化装置(エンコーダ)の一部として実装されています。
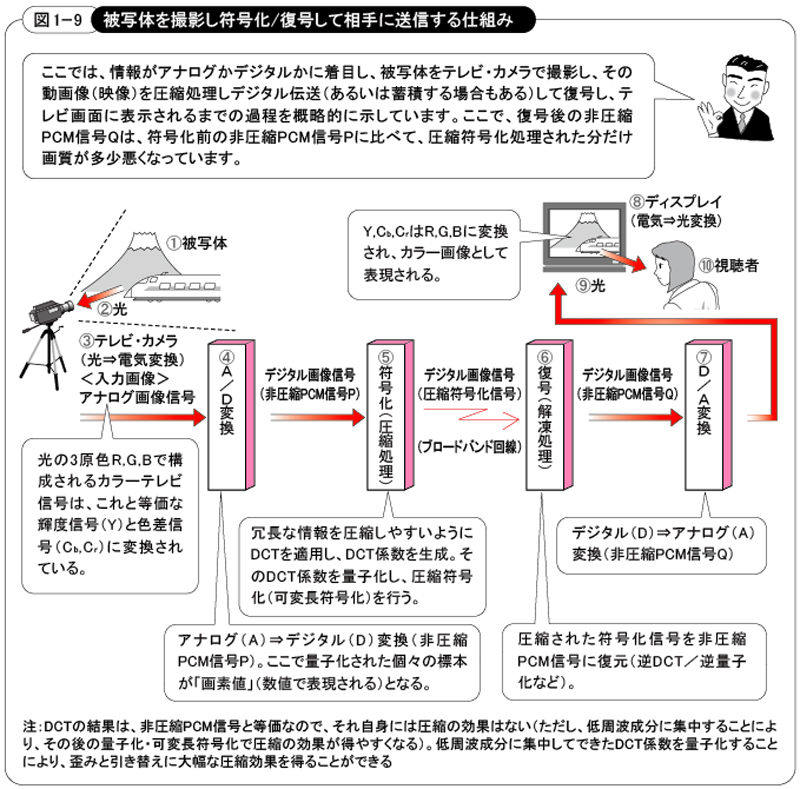
図1-9 被写体を撮影し符号化/複合して相手に送信する仕組み(クリックで拡大)
アナログ信号を標本化によってデジタル信号に変換(非圧縮PCM)した後は、個々の標本が「画素」(英語で「ピクセル:Pixel」という)となり、それは数値(例:4ビットの場合は「0010」)で表されますので、いろいろなデジタル処理が可能になります。
また、画素のままで画像を表現するよりも、後述するDCTによって等価な周波数成分に変換(これをDCT係数と言う)して表現することによって、画像の圧縮を容易にできるようになります。
次に、この周波数成分(DCT係数)を例えば、後述する可変長符号化(エントロピー符号化。後述のQ.11参照)し圧縮することもできますが、H.264/AVCを含めて、現代の画像圧縮符号化は後述する「動き補償フレーム(画面)間予測」と「DCT」に「エントロピー符号化」を組み合わせた「ハイブリッド符号化」によって圧縮します。
動き補償フレーム間予測とは、時間軸方向に流れるフレーム(画面)間で、前画面(フレーム)をメモリ(フレーム・メモリ)に記録しておき、被写体の動きを考慮した予測画面と原画面の差分(すなわち予測誤差)のみを相手に送ることによって、前画面と同じ冗長な情報部分(例えば変化のない「山」の部分)を削減し、(「山」のように変化のない同じ画像部分は送らないで)圧縮する方法です。
※この「Q&Aで学ぶ基礎技術:最新の情報圧縮技術〔H.264/AVC〕編」は、著者の承諾を得て、好評発売中の「改訂版 H.264/AVC教科書」の第1章に最新情報を加えて一部修正し、転載したものです。ご了承ください。
バックナンバー
関連記事
Q&Aで学ぶH.264/AVC(11):圧縮技術の基本的な要素は?
2008年7月7日 0:00
Q&Aで学ぶH.264/AVC(5):どのような情報が圧縮されるのか?
2008年3月6日 0:00
Q&Aで学ぶH.264/AVC(6):ハイビジョンでも使われる「色差信号」とは?
2008年3月17日 0:00
Q&Aで学ぶH.264/AVC(13):圧縮技術の基本的な技術「可変長符号化方式」の特徴とは?
2008年7月18日 0:00
Q&Aで学ぶH.264/AVC(10):「H.264/AVC」は画像だけの圧縮技術か?
2008年3月31日 0:00
Q&Aで学ぶH.264/AVC(2):なぜ、圧縮技術が必要か?
2008年2月28日 0:00
筆者の人気記事
Q&Aで学ぶH.264/AVC(12):圧縮技術の基本的な技術「DCT(離散コサイン変換)」とは?
2008年7月14日 0:00
Q&Aで学ぶH.264/AVC(4):情報をデジタル化する仕組みは?
2008年3月4日 0:00
Q&Aで学ぶH.264/AVC(1):H.264とは? AVCとは?
2008年2月25日 0:00
Q&Aで学ぶH.264/AVC(11):圧縮技術の基本的な要素は?
2008年7月7日 0:00
Q&Aで学ぶH.264/AVC(13):圧縮技術の基本的な技術「可変長符号化方式」の特徴とは?
2008年7月18日 0:00
Q&Aで学ぶH.264/AVC(6):ハイビジョンでも使われる「色差信号」とは?
2008年3月17日 0:00
新着記事
新刊情報






