





富士通研究所、5,000万件を超える大規模データから機械学習により数時間で予測モデルを生成する技術を開発
2015年9月7日 (月曜) 0:00
2015年9月7日、株式会社富士通研究所(以下:富士通研究所、神奈川県川崎市、代表取締役社長:佐相秀幸)は、5,000万件を超える大規模データから機械学習により数時間で高精度な予測モデルを生成する技術を開発したことを発表した。
従来、精度の高い予測モデルを生成するためには、学習アルゴリズムや動作条件などすべての組み合わせを調べる必要があり、例えば、5,000万件規模のデータによる学習では1週間以上の時間を要していた。
同社の開発した技術は、少量のサンプルデータと過去の予測モデルの精度から機械学習結果を推定し、もっとも精度の高い結果の得られる学習アルゴリズムや動作条件の組み合わせを抽出して、大規模データの学習に適用する。これにより、5,000万件規模のデータであっても数時間で精度の高い予測モデルを得ることが可能となる。
同技術を用いた予測モデルにより、大規模ECサイト会員の退会抑制や設備の故障対応の迅速化といった改善をタイムリーに実現できる。
◆技術の特徴
- 機械学習の実行時間と予測精度を推定する技術
代表的な機械学習のアルゴリズムに関して、データ件数やデータの特徴を表す属性の数を変えながら実際の機械学習の実行時間を計測し、これらの実測値を基に実行時間の傾向を表す実行時間モデルを構築した。実行時間の実績に基づいた実行時間推定の補正も実施して推定精度を向上している。過去に実施したアルゴリズムや動作条件の組み合わせと、得られた予測モデルの精度をデータベースである性能ナレッジに記録しておき、新しい組み合わせの予測精度を推定する。これにより、少量のサンプルデータでも予測精度を損なわない必要最小限のデータ量を見極めることができる。
実行時間と予測モデルの精度の推定により、高速かつ高精度な予測モデルの生成を実現している。従来、1つの機械学習アルゴリズムの中で予測精度を推定する技術は存在したが、複数の機械学習アルゴリズムと複数のデータ量に対して適用する技術はなかった。本技術は、機械学習を行うたびに、その時の条件(アルゴリズム、データ件数、属性数、インフラ情報など)と実際の実行時間を記録して推定に反映するので、使えば使うほど正確な推定ができるようになる。
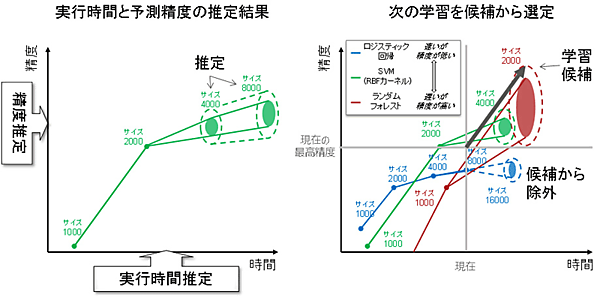
- 機械学習アルゴリズムを自動的にチューニングする制御技術(図参照)
あらゆる組み合わせの候補の中から時間効率の高い学習を選び出し、効率的かつ並列に学習を繰り返す技術。従来はどの順番でどの組み合わせの機械学習をすれば良いか決め手がなく、分析者のノウハウに頼った手探りで分析が進められてきた。同技術では、実行時間と予測精度の推定結果を総合判断し、予測精度が上がる可能性が高く、かつ短時間に実行が終わるアルゴリズムと動作条件の組合せを複数抽出して、並列に実行する。これにより、実行時間を考慮に入れた最適な順番でアルゴリズムを実行することができ、短時間で高精度な機械学習を選択することが可能となる。開発手法は、自動的に、より効果の高い組合せを集中的に選ぶように制御されているため、分析者のノウハウに依存しない。
図 機械学習アルゴリズムを自動的にチューニングする制御技術
◆効果
同社内実験で5,000万件規模のデータを12CPUコアのサーバ8台で処理したところ、従来、1週間程度かかっていた精度96%の予測モデルを、同技術では2時間強で得られることが確認された。また、3,000万件規模のWebアクセス履歴のデータを用いたアクセス分析において、本技術を用いた機械学習の適用が実用的に可能であることも確認された。
同技術により、例えば、首都圏の世帯を対象にしたエネルギー需要予測や、数十万人規模のサービスにおいて素早く退会の兆候を予測するなどのサービスが実現可能となる。
今後、富士通研究所は、ビッグデータを活用する富士通Analyticsソリューションなどでの実証実験を通じ、本技術の2015年度中の実用化を目指す。
■リンク
富士通研究所
関連記事
NEC、ビッグデータの予測分析期間を短縮する「特徴量自動設計技術」を開発
2015年8月18日 0:00
NEC、太陽光発電による余剰電力の抑制量を適切に配分する出力制御技術を開発
2015年8月24日 0:00
IBMの気象予測・解析システム「Deep Thunder」と発電量予測ソリューション「HyREF」
2014年7月1日 0:00
富士通とインテル、IoTプラットフォーム連携で合意
2015年5月13日 0:00
AI社会の実現へ。NICTが6Gに求められる「多数接続性能」を実証! 〜量子コンピュータを利用した同時通信に成功〜
2月16日 17:52
高速化する東京電力のスマートグリッド料金システム ―前編―
2014年1月1日 0:00
筆者の人気記事
新着記事
新刊情報






