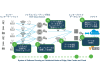
フォグコンピューティングとクラウドコンピューティングのシステム構成の違い
〔1〕クラウドコンピューティングの場合
フォグコンピューティングとクラウドコンピューティングのシステム構成の決定的な違いは何であろうか。
クラウドを技術的に表現すると、①コンピューティング(サーバ)と②ストレージと③ネットワークが一体化されたデータセンターを、物理的にというよりは論理的に構築し運営しているものである。ところが、クラウドにおける通信インフラ(ネットワーク)やアプリケーション、サービスを見ると、クラウドの大半の機能は、アプリケーションを処理しているコンピューティング(サーバ)とストレージに集中していることがわかる。ネットワークは、あくまでもコンピューティングとストレージなどのリソースをつなげるため存在している。
〔2〕フォグコンピューティングの場合
これに対し、エッジといわれるフォグコンピューティングの場合は、それ(コンピューティングとネットワークの比率)が逆転するとまではいかないが、コンピューティングとネットワークの機能の割合が比較的バランスがとれた構成となる。クラウドのインフラの場合、ネットワークが果たす割合は15%程度でしかない。すなわち、クラウドの大半のリソースはストレージとサーバコンピューティングになる。
一方、フォグコンピューティングの場合は、データの高速なやり取りが重視されるため、ネットワークの機能が50%近くにも達し、残りの50%がコンピューティングとなる(場合によってはストレージも置かれる)。
〔3〕クラウドとフォグの切り替え
その場合、フォグのところで処理する作業と、大もとのクラウドのサーバで処理する作業の切り替えは、アプリケーションのつくりによって行われる。すなわち、これまで中央のクラウドで処理していた一部を、身近な足元(クラウドの入り口)のフォグに分散して処理するというようなイメージになる。
例えば、東京・六本木のミッドタウン地域の現在の気象状況を観測して、それに基づいて空調の温度を制御したりする場合、そのような処理はもちろんセンターのクラウドでも可能であるが、もっと近いエッジ(ミッドタウン地域)で処理したほうが空調制御を細かく、しかも早くできるようなメリットがある。
ビッグデータとも関連するフォグコンピューティング
また、フォグコンピューティングは、ビッグデータの処理とも密接に絡んできている。一般に、現在、ビッグデータの多くはクラウドの中で処理されているが、今後、ビッグデータの処理機能の一部はエッジのほうに分散して配置されるようになる。
すなわち、フォグコンピューティングは、
- クラウドの手前のフォグ(エッジ)でビッグデータを分析し処理する機能(処理時間のかかる大きなデータはクラウド側で処理)と、その結果をユーザー側に送信する役割
- 同時にエッジで分析/処理した結果をクラウド側に送り、元データとして蓄積しておく役割
の2つの役割を果たすことになる。このため、今後、ビッグデータの処理においては、このフォグコンピューティングとクラウドコンピューティングの間で、広く役割分担が行われるようになると見られている。
今後シスコは、このように両者の役割分担を明確にしながら、ビッグデータの分析/処理を高速に、効率よく処理することを目指して、IoTを強化しようとしている。