





電力業務に特化したLLM開発へ、中国電力が検証
RAGの精度課題を解消、26年度以降に実用化2026年1月27日 (火曜) 9:45
電力業務に特化したLLMを構築へ
中国電力株式会社(以下、中国電力)は、電力業務に特化したLLM(Large Language Model:大規模言語モデル)注1を構築する。NTTドコモビジネス株式会社(以下、NTTドコモビジネス)と共同で構築し、2026年1月から3月末にかけてLLMの精度を検証する。検証結果を踏まえ、2026年度以降に実用化する計画だ。2026年1月26日に発表した。
汎用技術では困難だった専門知識に対応
電力業界には法令や官公庁の規制に基づいた厳格な基準があり、電力会社は行政機関へ提出する書類の作成や確認に時間を要している。この課題を解決するため、中国電力は、NTTドコモビジネスと生成AIアプリケーションの開発を進めてきた。しかし、生成AI技術による誤情報の出力を防ぐために外部情報を参照する「RAG注2」などの汎用的な技術では、電気事業の専門知識や企業固有の業務情報に対し、回答の精度を十分に確保できないケースがあった。
こうした課題を解決するため、今回、日本語処理に強みを持つLLM「tsuzumi 2注3」(NTT株式会社製)に、電気事業や中国電力の独自データを学習させることで、実務に即した高度な判断を支援するLLMの構築を決定した。
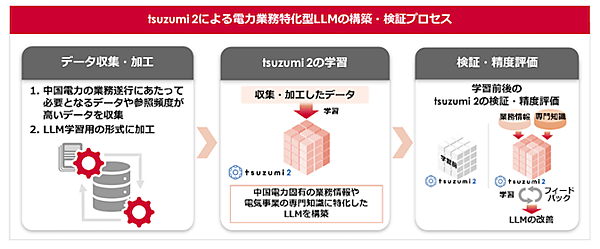
LLMの構築にあたり、中国電力が、社内のマニュアルや手引、過去の行政機関への申請書類など、業務遂行にあたって必要となるデータや参照頻度が高いデータを中心に収集する。それらを、NTTドコモビジネスがLLMの学習に適した形式へ加工し、インターネット上の公開情報などと合わせてLLMに学習させ、電力業務特化LLMを構築する。
構築後は、専門用語や業務情報に関する回答の精度を、LLMの学習前後で比較、分析する。精度の評価には、業務で調べる機会が多い事項などをまとめたQA集を使用する。評価結果を踏まえ、NTTドコモビジネスがLLMの再学習を実施し、精度を改善する。
今後、中国電力は、業務領域での生成AI技術の活用により、業務変革を進める。
注1:LLM(Large Language Model:大規模言語モデル):大量のテキストデータを用いて学習された、言語の理解や生成において高い能力を持つAI技術。
注2:RAG(Retrieval-Augmented Generation):LLMが回答を生成する際、外部の信頼できる情報を検索・参照して推論の精度を高める技術。
注3:tsuzumi 2:NTT株式会社が開発した、日本語の処理能力に強みを持つ国産のLLM。
- この記事のキーワード
関連記事
筆者の人気記事
新着記事
新刊情報






