





ソフトバンクと米Ampere社が低消費電力「CPU」でAI推論の最適化を実証
独自最適化によって消費電力抑制と高速化を両立2026年2月27日 (金曜) 14:21
CPUを活用しAIモデル運用を効率化
ソフトバンク株式会社(以下、ソフトバンク)は、2026年2月17日、半導体設計企業である米Ampere Computing LLC(以下、Ampere社)と、CPU注1を活用し、AIモデルの運用効率を高める共同検証を開始したと発表した。
今回の検証では、ソフトバンクが開発する計算資源管理用のオーケストレーター注2と、推論処理向けに設計されたAmpere社製CPUを組み合わせ、小規模言語モデル(SLM)注3やMixture of Experts(MoE)注4などの推論をCPU上で効率的に実行できることを確認したという(図1)。
図1 ソフトバンクとAmpere社の実証では、複数の推論モデルをCPU上で並行して実行しAIモデルの運用を最適化する
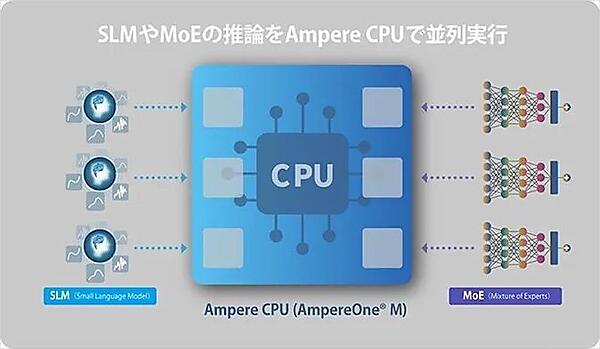
SLM:Small Language Model、小規模言語モデル
MoE:Mixture of Experts、推論の際、モデル全体ではなく、特定の処理に適した「専門家(Expert)」パーツのみを動作させることで、計算負荷と消費電力を抑える手法。
出所 ソフトバンク株式会社 プレスリリース 2026年2月17日、「ソフトバンクとAmpere、CPUを活用して小規模AIモデルの運用を効率化する共同検証を開始」
オーケストレーターで計算資源を最適配分
今回の共同検証では、分散型の計算環境を想定し、CPUのみを搭載したノード注5やGPU注6併用ノードが混在するマルチノード環境で、オーケストレーターがユースケースや負荷などの特性に応じてAIモデルを柔軟に配置・管理し、最適化できることを確認した。
さらに、オープンソースのAI推論フレームワークである「llama.cpp注7」をベースに、Ampere社製CPU向けに最適化した「Ampere optimized llama.cpp」注8を実装した。この最適化によって、一般的なGPUベースの構成と比較して、消費電力を抑えながら同時実行可能数を増やせることを確認。これに加えて、AIモデルの読み込み時間が大幅に短縮され、モデルの高速な切り替えも可能となったという。
今後、両社は、複数のモデルを動的に切り替えながら、TPS注9を安定的に維持できるAI推論プラットフォームの実現に向けた取り組みを進めていく。ソフトバンクは、次世代AIインフラを支える要素技術の1つとして、低遅延かつ高効率なAI推論環境の確立を目指す。
ソフトバンクによると、AI技術が普及するなか、大規模言語モデル(LLM)だけでなく、特定の用途に特化して高い実用性を発揮するSLMの需要が拡大しているという。特にAIエージェントやネットワーク制御などの分野では、低遅延な応答性と常時稼働を前提とした高い電力効率を兼ね備えた推論処理が求められている。
注1:CPU:Central Processing Unit、中央演算処理装置。コンピュータの汎用的な制御や演算を担う。
注2:オーケストレーター:Orchestrator。複数のシステムやサービス、アプリケーションの管理、統合、自動設定を行う仕組み。
注3:SLM:Small Language Model、小規模言語モデル。LLMと比較してパラメータ数が少なく、特定のタスクにおいて軽量・高速に動作するよう設計されたモデル。
注4:Mixture of Experts(MoE)、推論の際、モデル全体ではなく、特定の処理に適した「専門家(Expert)」パーツのみを動作させることで、計算負荷と消費電力を抑える手法。
注5:ノード:ネットワーク環境において、処理を行う個々のコンピュータやサーバのこと。
注6:GPU:Graphics Processing Unit、画像処理や膨大な並列計算に特化した演算装置。AI推論にも多用される。
注7:llama.cpp:ラマ・ドット・シー・プラス・プラス。大規模言語モデルを効率的に動作させるためのオープンソースの推論フレームワーク。
注8:Ampere optimized llama.cpp:Ampere社製CPU向けに、計算効率や処理速度を最適化した改良版フレームワーク。
注9:TPS:Tokens Per Second、1秒当たりのトークン出力数。AIが文章を生成するスピードを示す指標。トークンとは、LLMが文章やデータ等を処理する場合の最小単位。
参考サイト
ソフトバンク株式会社 ニュース 2026年2月17日、「ソフトバンクとAmpere、CPUを活用して小規模AIモデルの運用を効率化する共同検証を開始」
- この記事のキーワード
筆者の人気記事
新着記事
新刊情報






