





OpenAIによって開発された、生成AIチャットボットであるChatGPTが2022年11月に一般公開されて以降、AIはめざましい進化を遂げてきた。当初、主にテキストや画像の生成といったデジタル空間の中での進化に注目が集まっていたが、こうした状況に大きな変化が訪れている。それはフィジカルAIである。
フィジカルAIとは、カメラやセンサーを通じて現実世界を認識し、ロボットや自動運転車などを通じて物理的に行動するAIシステムの総称である。このフィジカルAIについて見ていく。
フィジカルAIの“ChatGPTモーメント”が迫ってきている
CES 2026におけるNVIDIA(エヌビディア)のCEO ジェンスン・フアン(Jensen Huang)CEOの基調講演で紹介された動画の中で、「フィジカルAIの“ChatGPTモーメント”が迫ってきている(The ChatGPT moment for physical AI is nearly here)注1」という象徴的なメッセージが示された。ChatGPTの登場が社会に与えたような変化が、フィジカルAIにおいても起きることを示唆するようなメッセージである。
フアン氏の動画における発言とは異なり、NVIDIAのプレスリリースでは “The ChatGPT moment for robotics is here.”となっている。
動画内では“is nearly here”(そこまで来ている)と抑え目のトーンになっているのに対し、リリースでは“is here”(到来している)と表現され、実現性が高まってきていることが伝わってくる。
フィジカルAIと日本のCPSのつながり
フィジカルAIにおける「サイバー空間とフィジカル空間の高度な融合」という概念は、実は日本ではすでに馴染みのあるものだ。2015年にJEITA(一般社団法人 電子情報技術産業協会)が、「CPS(Cyber-Physical System、サイバーフィジカルシステム)社会実装検討タスクフォース」を設置している。
実世界のデータをセンサーで収集し、サイバー空間でAIが分析し、その結果を現実世界にフィードバックするというCPSの構想は、フィジカルAIが目指す世界と重なる部分が大きい。ただし、CPSでは、センサーデータをサイバー空間(インターネット空間)で分析し、その結果を人間の意思決定や制御系に反映させることが中心であった。
一方、フィジカルAIでは、その意思決定プロセスをAIが担い、より高い自律性をもって物理的行動まで実行する点に違いがある。
フィジカルAIを支える技術の全体像
フィジカルAIを理解するうえで重要なのは、これが単一の技術ではなく、複数の技術の統合によって成り立っている点である。大きく分けると「認識」「判断」「行動」を司る3つの層があり、それらを結ぶ「通信ネットワーク」、そしてAIに物理世界の振る舞いを学ばせる「シミュレーション基盤」が全体を支えている(図1)。
図1 フィジカルAI技術層
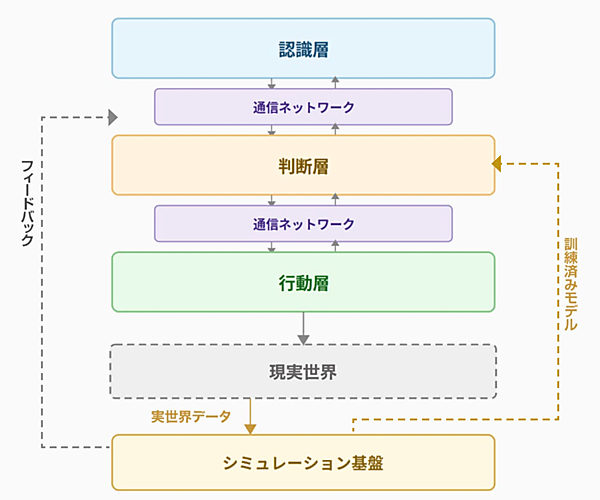
出所 各種資料を元に著者作成
[1]「認識層」を司るセンサー群
図1の最上部に位置する「認識層」は、フィジカルAIの「眼」にあたる。カメラ、LiDAR(ライダー。Light Detection and Ranging、光による検出と測距)、触覚センサー、IMU(アイ・エム・ユー。Inertial Measurement Unit、慣性計測装置)注2といったセンサー群が現実世界の情報を取得する。
例えば、工場内を自律走行するロボットであれば、カメラで周囲の障害物や作業対象物を認識し、LiDARで空間の三次元構造を把握し、IMUで自らの姿勢や加速度を検知する。これらの情報がリアルタイムで次の「判断層」に伝送される。
[2]「判断層」を担うVLAモデル
図1の中段に位置する「判断層」は、フィジカルAIの「脳」にあたる。ここでは、視覚(Vision)、言語(Language)、行動(Action)という3つの情報を統合的に扱うVLA(ブイ・エル・エー。Vision-Language-Action)モデルと総称されるタイプのAIモデルが重要な役割を担い始めている。
VLAモデルは、カメラの映像(視覚)と自然言語による指示をセットで理解し、ロボットの関節角度や移動経路といった物理的な指令を直接生成する。従来の産業用ロボットがあらかじめプログラムされた動作を繰り返していたのに対し、VLAモデルを搭載したロボットは、目に見える状況の変化に応じて「どう動くべきか」を自ら推論して判断できるため、未知の環境でも柔軟に対応できる点が根本的に異なる。
このVLAモデルは、Google DeepMind注3のRT-2(Robotics Transformer 2)注4によってその有効性が広く示された。その後、Google DeepMindの他、スタンフォード大学やUCバークレー、そしてトヨタ・リサーチ・インスティテュート注5などの共同研究グループがOpenVLA注6というオープンソースVLAモデルを公開している。
その他、NVIDIAによる人型ロボット専用の基盤モデルであるGR00T注7など、多くの企業や研究機関が独自のモデルを開発・公開している。
[3]現実世界で作用する「行動層」
図1の下段に位置する「行動層」は、フィジカルAIの「身体」にあたる。判断層からの指令に基づいて現実世界に物理的に作用する部分であり、具体的にはヒューマノイドロボット注8や産業用協働ロボット、自動運転車、ドローン、AGV(Automated Guided Vehicle、無人搬送車)やAMR(Autonomous Mobile Robot、自律走行型搬送ロボット)などが該当する。
経済産業省のAIロボティクス検討会の参考資料では、ヒューマノイドを含む多用途ロボット市場の規模は2030年頃を境に急拡大し、2040年までに約60兆円規模に達するとの試算が紹介されている注9(図2)。
図2 多用途ロボット市場推移
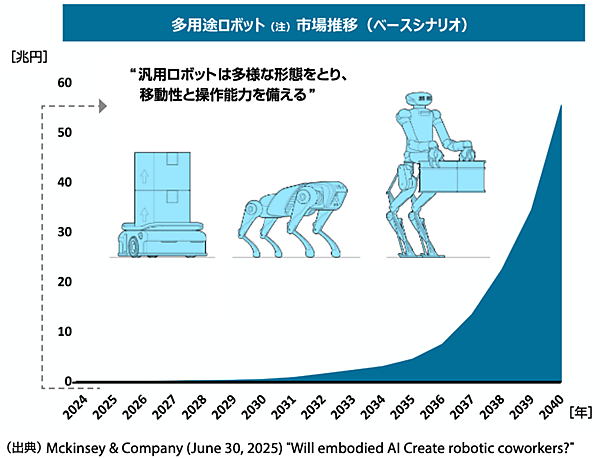
(注)ベースシナリオ(基本シナリオ)では、中国におけるロボット導入が一定の速度で進むことを想定している。
出所 経済産業省、『AIロボティクス検討会 参考資料』(2025年10月)5ページより、一部日本語化・修正して作成
AIモデルを安全に訓練する「シミュレーション基盤」
図1の最下部に配置した「シミュレーション基盤」は、判断層のAIモデルを訓練するための仕組みである。フィジカルAIの学習には、ロボットが実際に物を掴み、運び、組み立てるといった物理的な動作のデータが必要だが、実世界でのデータ収集には多大なコストと時間がかかるうえ、失敗すれば機器の破損や安全上の問題が発生する。
そこで、現実世界から収集した「実世界データ」をもとにシミュレーション環境を構築し、仮想空間内で大規模な訓練を行ったうえで、その成果を「訓練済みモデル」として判断層に供給するという流れが確立されつつある。
注1:YouTubeの“NVIDIA Live with CEO Jensen Huang”という動画の31分28秒頃で聞くことができる。
注2:加速度センサーとジャイロスコープからなるユニットを基本とし、ある物体の加速度と角速度を検出するための装置。(出所:https://product.tdk.com/ja/products/sensor/mortion-inertial/imu/index.html)
注3:Google DeepMind :英国でAIを開発しているAlphabetの子会社。
注4:RT-2: New model translates vision and language into action — Google DeepMind
注5:トヨタ・リサーチ・インスティテュート:Toyota Research Institute。米国シリコンバレーに2016年1月設立。
注6:OpenVLA: An Open-Source Vision-Language-Action Model
注7:GR00T:Generalist Robot 00 Technology、グルート。
注8:ヒューマノイドロボット:人間の頭や胴体、腕、脚などの構造や動作を模倣する人型ロボット。
注9:https://www.meti.go.jp/shingikai/mono_info_service/ai_robotics/pdf/20251008_2.pdf
バックナンバー
新着記事
新刊情報






