





2026年1月、まったく新しいGPUクラウドOS「Infrinia AI Cloud OS」(インフリニア・エーアイ・クラウド・オーエス、以下Infrinia と表記)」がソフトバンク株式会社(以下、ソフトバンク)から発表された。Infrinia Team注1によって開発されたこの新製品は、急速に拡大するAI市場において、リソースとして不可欠となっているGPU(Graphics Processing Unit、画像処理装置)を効率的に管理・提供するための新たなクラウド基盤ソフトウェアだ。これまで、GPUによるクラウド運用には制限や非効率な点が多かったが、それらの課題を解決し、AIデータセンター事業者をはじめとする多様な事業者がGPUクラウドサービス提供を可能とする。その最新情報をレポートする。
Infrinia誕生の背景:GPUクラウド市場の現状と課題
〔1〕現在までのGPUクラウドサービス市場
AIが隆盛を極める現在、これに伴いGPUの需要が世界的に急増している。そのため、AmazonやGoogle、Microsoftなどの既存のハイパースケーラーであっても、AI需要に対応する演算能力(GPU)の確保が追いついていない。そのような中、AIや大規模データ処理に特化して設計された「ネオクラウド」(Neo Cloud)という新たなクラウドの形態が登場し、CoreweaveやNebius Groupなどの企業が台頭してきている。これらの企業はGPU特化型のインフラを大規模に構築しグローバルに提供しているが、それでもAI需要に対する供給が追いついていないのが実情である。その結果、世界の各地域ではGPUクラウドを提供する事業者が増加しつつある。
現時点までのユーザー注2のAI利用用途の多くは「巨大なAIモデルの学習」、つまり大規模言語モデル(LLM)や生成AIモデルを大量データを使って学習させて予測能力を向上させる手法であるため、限られた企業や団体が、膨大なGPUリソース(数千〜数万基レベルの最新GPU)を長期にわたって半固定的に専有することが多い。
これらの用途においては、基本的にはユーザー側にもGPUインフラの運用や保守管理のための能力や人材が備わっていることが前提になっていたことから、GPUクラウド事業者が「素のままに近いGPUサーバ」(インフラ基盤のみ)を提供するIaaS(Infrastructure as a Service)形態の供給であっても、保守管理などに伴う事業者側の負担は、これまでは大きな問題になっていなかった。
〔2〕今後予測されるGPUクラウドサービス市場
今後、ユーザーのAIの利用は、推論や比較的小さな言語モデルの学習・チューニングなど、その利用範囲が多様化・高度化し、増大してくると考えられる。そのため、大企業だけでなく、これまでよりも多様で小規模な企業や団体もGPUクラウドを利用するようになる。
このような新たなニーズはこれまでと異なり、次のような特徴をもつGPUクラウドサービスへの要求が高まることが想定される。
(1)より小さいGPUリソースの単位から、柔軟かつタイムリーにAIを利用できる
(2)インフラ管理の負荷が低く、自社のリソースをAIモデルの開発や運用に集中できる
これらのニーズを満たすGPUクラウドサービスとしては、Kubernetes注3 as a Service(KaaS)や、Inference as a Service(Inf-aaS注4)が有用となる(図1)。
図1 AIの利用用途によって変わるインフラ形態「IaaS」「KaaS」「Inf-aaS」の位置づけ
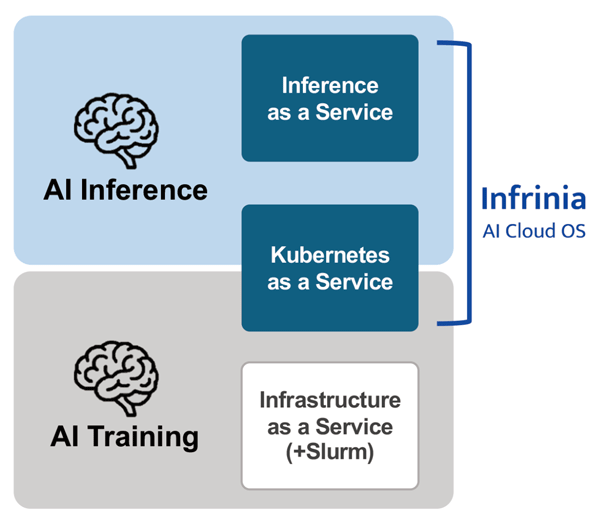
AIの利用用途が「モデル学習」から「推論」へと広がると、求められるインフラの形態も変化する。学習用途のみであれば IaaS で十分であるが、学習と推論の両方を並行して行う場合は、柔軟な運用が可能な KaaS が適している。さらに、推論の効率を最大限に高めるのであれば、推論特化型の Inf-aaS を活用するのが理想的だ。
しかし、これらのサービスを実装するためには、GPUクラウド事業者側に多くの高スキル技術者の確保と長期間の開発・運用が必要となり、インフラ構築能力をもたないユーザーニーズに対応するには、GPUクラウド事業者側の事業負担が大きくなる。ハイパースケーラーやネオクラウド企業のような大規模事業者は自前で実装ができるものの、世界各地域の多くのGPUクラウド事業者にとってはこの点が課題となっている(図2)。
このような課題を解決するために開発されたのが、Infrinia である。
図2 KaaSやInf-aaSの実装・提供のためにはGPUクラウド事業者は高スキル人材の確保や膨大な維持コストが必要
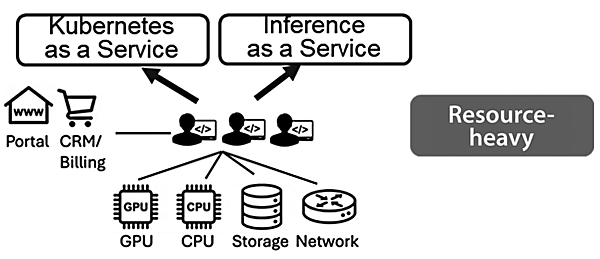
図の下段のGPU、CPU、ストレージ、ネットワークや、左側のユーザーポータル、顧客・請求管理システムは、事業者が保有する基本リソース群を示している。
図上部のKaaSやInf-aaSといった高度なサービスを実装・提供するには、専門性の高い技術者を多数確保し、開発と運用に投入し続けなければならない。こうしたリソース集約的(Resource Heavy)な仕組みにおいて、高スキル人材の確保の難易度や膨大な維持コストが、事業運営上の大きな負荷となっていることを図示している。
注1:Infrinia Team : ソフトバンク完全子会社であるSB Telecom America Corp. 内に設けられた開発チーム。米国カリフォルニア州サニーベールを拠点として活動中。
注2:ユーザー:ここでは「GPUクラウドサービスを利用する企業・団体」。
注3:Kubernetes:クバネティス。アプリケーションのデプロイやスケーリングを自動化したり、コンテナ化されたアプリケーションを管理したりするためのオープンソースソフトウェア(OSS)。Kubernetesの利用によって一括で自動管理することが可能となるため、システム開発や管理が大幅に効率化できる。
注4:Inf-aaS:Inference as a Service。高性能なGPUサーバなどのインフラ構築・管理を自前で行うことなく、LLMの選択だけで推論サービスを運用できる。
バックナンバー
関連記事
筆者の人気記事
新着記事
新刊情報






